Hashing - Algorithms for Competitive Programming

Hashing provides a way to quickly access and store data, ensuring efficient lookups, inserts, and deletions. It reduces the time complexity for these operations to nearly constant time, making it crucial for applications like databases, caching, and competitive programming, where speed is essential.
What is hashing?
Hashing is a method of sorting and indexing data. The idea behind hashing is to allow large amounts of data to be indexed using keys commonly created by formulas.
Concept : Imagine we want to store two words, Apple and Application and we have a python list over here to store. We will put Apple and Application through hash function which will turn them into numbers (suppose 11, 18). Afterwards, the words will be put into the 11th and 18th index on of the list. Now, we can access elements of array/python list based on their index which takes O(1) time complexity (super efficient)
Why we need it?
Let's say we want to develop an app where search operations are frequent and speed is necessary. In this case, we can use hashing because it performs better than other data structures for searching.
| Data structure | Time complexity for SEARCH |
| Array/Python list | O(logN) |
| Linked list | O(N) |
| Tree | O(logN) |
| Hashing | O(1) / O(N) (worst case) |
Hashing Terminology
Hash Function: It is a function that maps data of any size to data of a fixed size.
Key: Input given by a user
Hash Value: A value that is returned by Hash Function
Hash Table: It is a data structure that works like an associative array, allowing you to map keys to values.
Collision: A collision occurs when two different keys to a hash function produce the same output.
Hash functions
Mod function - works only for integer inputs.
it has two params - number, total cell number/ size of array. Based on this function, we find out the indexes and insert values in a cell. mod(400, 24) -> we will get 16 (400%24, remainder = 16). It means we can insert 400 to the 16th index.
def mod(number, cellNumber): return number % cellNumber mod(400, 24)ASCII function - Converting a string's characters by using
ordfunction.def modASCII(string, cellNumber): total = 0 for i in string: total += ord(i) return total % cellNumber modASCII("ABC", 24)
Properties of good Hash function:
It distributes hash value uniformly across hash tables (referring collision)
It has to use all the input data
Types of Collision Resolution Techniques
Imagine EGG, BUTTER - both of their output is 2. We can't put both of them in the 2nd index as it will cause a collision. How do we avoid it? We will learn resolution techniques for solving collision.
Resolution techniques can be solved in two ways:
Direct Chaining
Open Addressing
Linear probing
Quadratic Probing
Double hashing
Direct chaining: Implements the buckets as a linked list. Colliding elements are store in the list.
Open addressing: Colliding elements are stored in other vacant buckets. During storage and lookup these are fount through probing.
Linear probing: It places new key into closest following empty cell.
Quadratic Probing: Adding arbitrary quadratic polynomial to the index until an empty cell is found.
ABCD -> 2, EFGH ->2, IJKL -> 2
1^2, 2^2,3^2,4^2 ...... (quadratic series)
2 + 1^2 = 3 ; 3rd index for EFGH
2 + 2^2 = 6 ; 6th index for IJKL
Double hashing: Interval between probes is computed by another hash function
first hashing: ABCD -> 2, EFGH -> 2, IJKL -> 2
second hashing: EFGH -> 4, IJKL-> 4
Now, 2 + 4 = 6 ; 6th index for EFGH
2 + (2*4) = 10 ; 10th index for IJKL (1st hash value from the 1st hash function plus 2 times the 2nd hash value from the 2nd hash function)
Hash table is Full
If a hash table is full, what do we do? Let's break down.
If we use Direct chaining:
This situation will never arise. In this case, if we continue to insert more elements, it will be assigned to another node from the index. So, hash table will never be full.
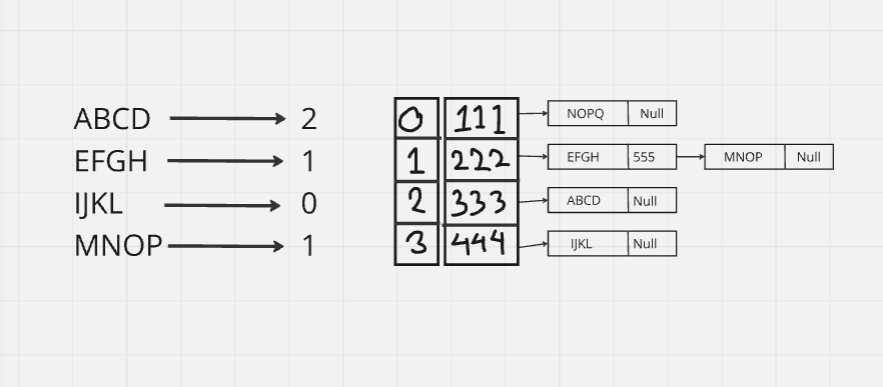
If we use Open addressing:
Create 2X size of current Hash Table and recall hashing from current key
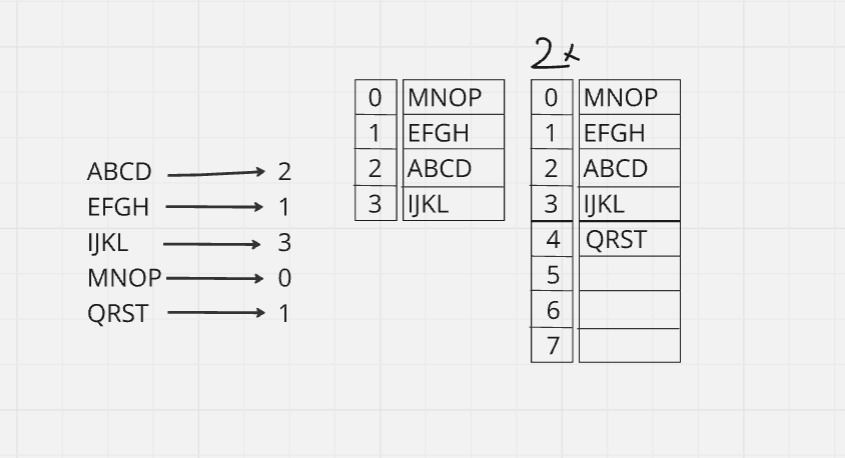
Pros and Cons of Resolution Techniques
Direct chaining's main advantage is that the hash table never gets full, allowing unlimited element insertion. However, as more elements are added, the linked list grows, increasing the time complexity. Searching for an element can become O(N) instead of O(1), which defeats the purpose of using hashing for quick searches.
Hash table never gets full
Huge linked list cause performance leaks
Open addressing is easy to implement. We create an array based on a hash function and assign values to it. However, when the hash table gets full, we must create a new one and reassign values, which affects performance. If there are N elements, it takes O(N) time to reinsert them, reducing hashing efficiency.
Easy implementation
When hash table is full, creation of new hash table affects performance.
How to chose? The answer is simple.
If the input size is known, we will use open addressing. Because in this case, we don't have to create a new hash table which will be time efficient.
On the other hand, if deletion operation is very high, then in that case we should use direct chaining. We will not use open addressing with frequent deletions because gaps created by deletions cause linear probing to stop at empty cells (performance leak), incorrectly indicating that an element is missing even if it is right after the empty cell. Direct chaining does not create any empty cells in hash table.
Practical use of hashing
Password verification and security
When we enter our password, it gets converted into a hash value. The server then checks if this value exists in the database or not.
Hashing is also used to prevent direct exposure of passwords if the database is hacked. Even if a server gets hacked, the hacker won't find the passwords because hashing is one-way traffic. This means we can only get the hash value from the key, but we can't get the key from the hash value.
File system
File path is mapped to the physical location on the disk. The file path is taken as a key and converted to a hash value. This hash value is used to store the file's physical location on the hard disk. The path is the index, and the physical location is stored in the hash table. Based on the hash value, we get the file's physical location on the hard disk.
(The actual process is more complex than explained here, but the logic is same)
Hashing vs other DS
| Pros of hashing | Cons of hashing |
| On average insertion/deletion/search operation takes O(1) time complexity | When hash function is not good enough, insertion/deletion/search operations takes O(N) time complexity |
| Operations | Array/Python list | Linked list | Trie | Hashing |
| insertion | O(N) | O(N) | O(logN) | O(1)/O(N) |
| deletion | O(N) | O(N) | O(logN) | O(1)/O(N) |
| search | O(N) | O(N) | O(logN) | O(1)/O(N) |




